
We’re back! Hi to all of you! Guido Söldner and I finished analyzing Kale and Kubeflow within vSphere with Kubernetes. The following blogposts are categorized in different parts, where we highlight how you’ll get Kubeflow with Kale up and running in a multi-tenancy environment – which is not yet fully supported by Kubeflow. But we wanted to explore it either way. Spoiler: It works – again!
What to expect
At the end of the series, your Kubernetes will host Kubeflow with the Kale extension. You’ll fix mission critical errors by applying already pushed docker images (or create them by yourself). The code will be presented and explained. And finally, you will have seen all the right tools for applying your own extension i.e. did you know about Elyra? 🙂
Prerequisites: What did we already do?
We’ve already set up a Kubeflow installation, which you can find here. This is necessary for following this series! It’s not really necessary for you to do the followup LDAP/AD Integration, because some of that is obsolete already, as we found a better, long lasting solution.
How do we reach our goal?
This series will contain 4 blogposts:
- What are we going to do – Overview? This post
- Writing an extension regarding vSphere with Kubernetes
- Writing an extension regarding Kubeflow multi-tenancy issues
- Example utilization of Kale
Let’s start by providing some knowledge, so we can better explain what we’re going to do.
Kale and Kubeflow
Kubeflow has core functionality, i.e. Kubeflow Pipelines, Kubeflow Katib, Jupyter Notebooks.
The Notebooks component will create a Jupyter instance for us. Allowing us to prototype, utilize infrastructure e.g. high-speed network, and gives us access to components within Kubeflow.
We utilize Pipelines for the generation of Machine Learning pipelines. When a Machine Learning Project is done, it’ll consist of multiple steps: Data Loading, Transforming, Training, Serving and more, i.e. a Pipeline. All these steps may be encapsulated. A container is utilized to freeze the environment, becoming reproducible. For example: Data loading may need other Python libraries than model training. We shouldn’t download the data and finally change our library in the same code to fit our needs. Each step is now a bit more unentangled. Kubeflow Pipelines additionally let’s us view these steps in a graph, compare pipelines and much more.
When you want to find out which neural network architecture is best suited, or if you want optimize hyperparameters, then Katib is a great fit.
Well. That was the good.
Followed by the bad:
You want to utilize Kubeflow Pipelines? Cool learn this Python DSL, create your pipelines. Now perform Hyperparameter Search with Katib. But WAIT! To start, learn this fresh new shiny syntax (it’s only YAML, but you get the gist).
Finally, the ugly:
It does not “just work”. Kubeflow is rather new. Kale is rather new. Both are in active development. Finding out how to utilize Kale is not that easy. We were confronted with one issue after another, leading to deep insights of Kubeflow and Kale. The fixes are rather small. The debugging sessions rather long. We needed to write Admission Controllers. Watchers with the fabric8io Kubernetes Clients. Add new Roles. But what’s left to say? It’s still possible! And we will provide the source-code in our GitHub Repositories!
Kubeflow Pipelines
A Pipeline consists of multiple steps. View it as your CI/CD pipeline. Data is loaded, the output is taken, and given to another step. And so on, and so forth.
One Pipeline is 1:1 mapped to an experiment, were different configuration of this pipeline may be checked out, i.e. greater hyperparameter search space. An experiment is 1:N mapped to a run. This run may be recurring or not. A run may differentiate the input parameters of the Pipeline.
Kubeflow Pipelines DSL
Utilizing Kubeflow Pipelines can be as easy as wrapping some functions with a Python Decorator and finally calling kfpClient.compile. This can be done from your local workstation or withinin a Jupyter Notebook. Unfortunately, this does not work seamlessly with Kubeflow multi-tenancy, therefore we’ll hit an error, which we need to fix.
Katib
Katib is utilized with .yaml files. When an experiment as .yaml is pushed to the API-Server, Katib will do its deed.
The complete workflow is something like this. An experiment is found, based on the parameters, different trials (i.e. runs) are created. TheTrial creates a Job, which finally creates a Pod. This Pod contains two containers:
- the main container, running arbitrary code
- the side-car “metrics-collector-and-logger” trying to obtain the output of the main container, writing the results into the main
When both containers ran, the pod terminates. This will finish the job, which will finish the trial until all trials have finished. The experiment is now done.
Additionally, another Pod is created, which will generate example input data, based on the configuration of the experiment. You don’t necessarily want to test i.e. nodes by number: 1, then 2, then 3. You want to find the best possible configuration based on all your finished trials. How this is actually integrated is not necessary for us to know.
Kale
How does Kale come into play?
Kale is a Jupyter Hub Add-On utilizing Kubeflow Pipelines and Katib. You can flag different cells e.g. as input cell, or metrics cell. Based on these flags kale will generate a Kubeflow pipeline for you. Abstracting all the new shiny syntax away from you. Additionally, if that’s what you desire, you have a graphical wizard for setting up a Katib Hyperparameter Search.
You write some python code in your IDE, flag some cells and voilà. Let the bare metal architecture run 5 experiments in parallel while logging all the output and telling you which is the best architecture. All these is visible in Katib with pretty graphs and much more.
How does Kale work internally?
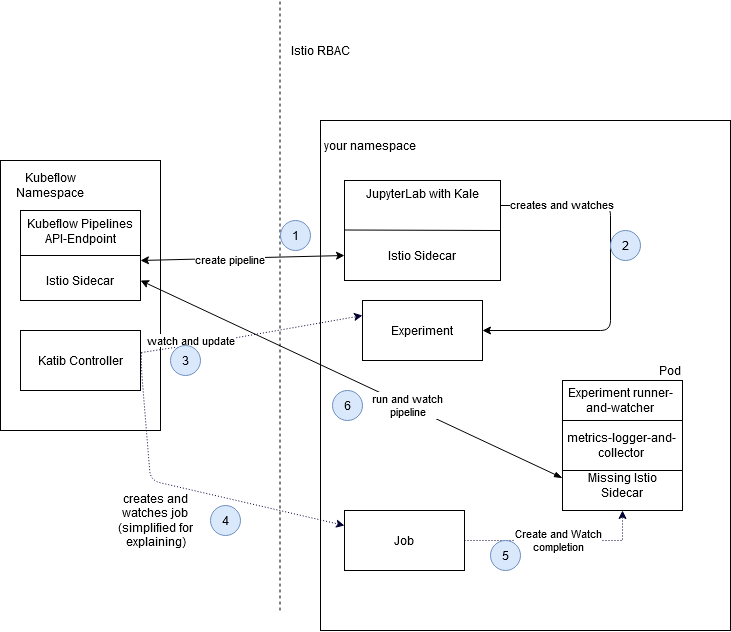
We are going to provide an image. Kale will utilize that as the base for each container. After that, Kale will wrap all the code into Kubeflow Pipelines DSL. The pipeline is sent to Kubeflow Pipelines Api Endpoint (1).
When the Pipeline is created, Kale will create a .yaml file for Katib, i.e. creating an experiment (which will create a trial -> job -> pod). A pod is finally started (5), where Kale does again call Kubeflow pipelines (6) for execution of a pipeline. (which was sent earlier to Kubeflow). The provided python code (6) calls Kubeflow pipeline every 30 seconds, checking whether or not the execution already finished. When everything ran successfully, the metrics will be extracted and written into a file. The container is stopped and the second container of the pod will collect the metrics and will save it to the Katib db. Finally, the pod stops and the job registers the completion of the job, closes the trial…
Some of the problems we’re going to fix
Somewhere in this process Read-Write-Many PVC may be created (?).
- 1) Kale can’t access Kubeflow Pipelines. We need to open up Istio access for the pod (multi-tenancy issue)
- 5) The pod can’t bypass Istio, therefore we need to inject an Istio sidecar
- 6) Same as 1
- 6) Two problems regarding the code:
- It’s not fault tolerant.
- It’s called too early (yes, yes… this will be a sleep.)
- ?) vSphere with Kubernetes and Tanzu does not support Read Write Many
These are only some of the issues. We introduce new problems by fixing some of them. I.e. injecting a Istio sidecar into the job will cause an endlessly running job / pod. We need to shut down the sidecar, by injecting some additional bash code.
While all these problems bubbled up, we’ve got some interesting insights… Did you know, that Kubernetes may log each call, and if one of those calls exited with anything except 0, the job will fail? And even though, if you explicitly return 0, the job still fails? Even though you redirected stderr and stdout? Yes. That’s the stuff you learn with us on this journey.
We’ll revise all these information in greater detail in the next posts.
I want that for my colleagues!
You are at the right place. We’re here to tell you how. We’re here to give you insights for the why. And the when doesn’t really matter. It’s Kubernetes.
Thanks for your attention, I hope to see you back soon!
Recent Comments