
Since Version 4.0.1 there is the possibility to create an active/active T0 allowing stateful operations.
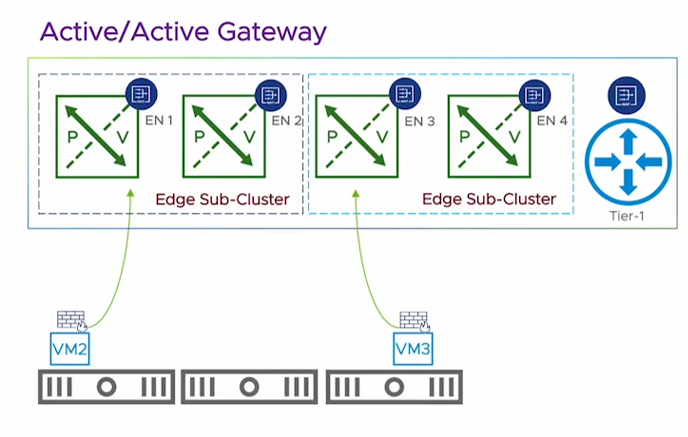
In principle this is implemented in a way, that a specific flow will always be treated by one Edgenode based on an edge node internal hashing algorithm. If the traffic lands on another edgenode, the traffic will be internally forwarded to the correct edgenode for treatment.
For redundany a second edge-node will be used as backup if the first one is unresponsive.
If you want to get some details about this mechanism or if you are not aware about the details, I highly recommend reading this excellent 4 part blog first:
https://vxplanet.com/2023/01/24/nsx-4-0-1-stateful-active-active-gateway-part-1-single-tier-routing/
What is not decribed in detail in this blog are the implied consequences:
If a NSX System for example has 4 edgenodes with one uplink each, a stateful active/active aware ECMP mechanism would in 3 out of 4 cases forward the traffic to the wrong edgenode. Such traffic (75% of the combined uplink traffic in our case) has to be sent over the Data-Center network from the wrong edgenode to the correct one. Assuming a recommended setup, every edge node is either a separate bare metal or in the VM case reside on a different transport node. This leads to the fact that the Datacenter has to forward75% of the uplink traffic twice. And in the current implementation this happens for the incoming and outgoing traffic in an equal manner.
But couldn’t it not have been implemented in a better bandwidth saving manner ?
Lets start our detailed consideration by looking into the currently used hashing algorithm:
This algorithm is based on the outside (public) destination address. As the amount of outside addresses is nearly infinite it will give a good spreading of flows over the available ECMP edge nodes.
Mechanism 1: for packets from inside to outside the T0-DR (Distributed Router) select the edgenode where the packet will be forwarded, but it uses a standard ECMP-hash ( 5-tuple) thus sending 3of 4 packets to the wrong edgenode.
Critics 1: why is the new hashing algo not implemented into the DR thus saving a lot of bandwidth for outgoing traffic ?
The used hashing algorithm also means that an upstream router would need to implement a matching hashing algorithm based on the Source-address of the packet to forward. Typically router vendors have implemented up to 4 (e.g Palo Alto) ECMP hashing algorithms but I a not aware of any router vendor using a hash based on the source addresses.
Critics 2: as a consequence by using this describe hashing algorithm any upstream router has no chance to know the correct destination edge node for a packet.
In general, how can any upstream router be informed which link to send a specific packet
Method 1: by means of a dynamic routing protocol specifying the correct next hop as the best
Method 2: by sending a (Gratuitous-)Proxy-ARP (https://en.wikipedia.org/wiki/Proxy_ARP, https://wiki.wireshark.org/Gratuitous_ARP.md), specifying the correct next-hop address if a packet lands at the wrong edge node.
Method 3: by sending an ICMP redirect message if edgenode uplink is in the same network
NOTE: I call it Gratuitous-Proxy-ARP as both basic mechanisms are true. It is an arp reply not requested by any sender and it contains a MAC-address which does not directly belong to the destination address. Alternatively IP-redirect could be used but is often disabled due to security reasons.
However BOTH methods only work for decisions based on the destination address of a packet, as L3 routing is destination based routing, so they cannot be used with the implemented hashing algorithm
NOW my proposal:
Step 1: modify the hashing algorithm by using the inside source address as base (for packets coming from outside and for the upstream router the decision is based on the destination address)
Step 2: Implement the hashing algorithm into the T0-DR
Step 3a: Implement the sending of (Gratuitous-)Proxy-ARP, on upstream links when a packet hits the wrong edge-node, to signal the correct inside destination, so that only the first packet need to be internally forwarded to the correct edge-node
Step 3b: Implement the sending of ICMP redirects if all edgenodes have the uplink interface in the same network (VLAN)
Step 4: Implement a different sending of routing updates for /32 (IPv6 /128) hostroutes by using either different OSPF-cost or BGP-MED to signal the best (correct) edge-node for the upstream router
NOTE: for Step 4 to be effective, the NSX administrator should specify /32 (/128 for IPv6) hostroutes for important and high volume destinations (like VIP address of load balancers).
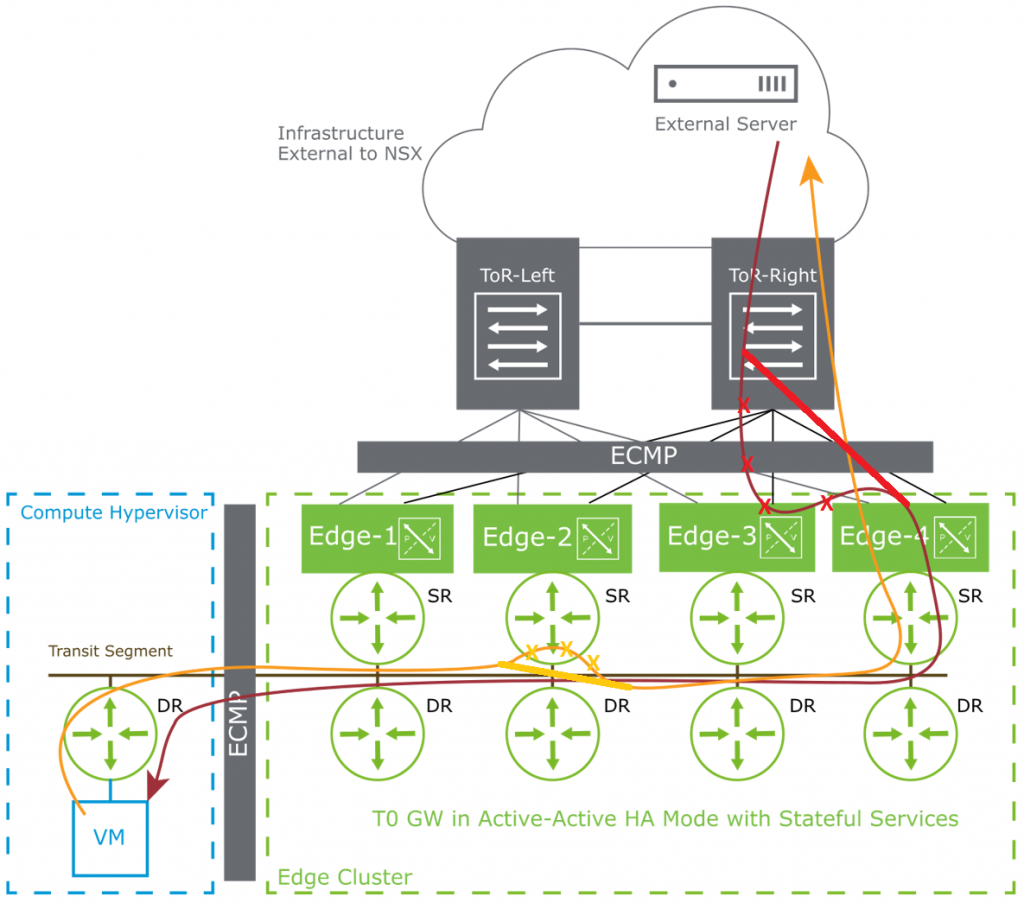
Using the proposed changes in the algorithm the author assumes that the traffic overhead will be decreased from 75% to less than 1%
One slight drawback in my opinion is the fact that there are typically less inside addresses than outside addresses so the distribution of flows is less efficient, but saving 75% of the combined uplink traffic from being sent over the DC-network is a much higher gain.
The other drawback is the larger per destination address ARP table on upstream routers or an increased routing table with more host-routes.
Another mid-term possibility would be to define a new Hash Algorithm Propagation-Protocol (HAPP) in an RFC to exchnge the hashing algorithm and results between T0 and Upstream Routers, which on their side can implement a HAPP Instance (HAPPI).
Last but not least VMware could program an open vswitch as an ECMP distributor with the correct hashing algorithm to be established between the T0 and the Upstream router(s).
Recent Comments