
Welcome back to the second part of this series, where I’ll setup kubeflow in a vSphere environment. Today I’ll review all the steps I’ve done to setup Workload Management in vSphere. Sure, we’ve got plentiful resources already. This post tries to highlight where other tutorials are glossing over – e.g. here are 10 text fields for CIDRs, fill it out.
If you missed the first part, I’ll recommend reading it. It’s short, concise and will give you a brief understanding on what we’re working on.
Want to save time? Read every sentence while setting up.
Setting up Workload Management presents some lousy traps, and you should be sure to read each document till the last sentence. My experience as a programmer has misled me. I’ve skimmed too much, and have overread one or two information, which later popped up as errors. Unfortunately, the documents are somewhat sprinkled around the web, which, in my opinion, encourages skimming. Later in this post I’ll highlight some of these errors.
The first steps
Open up the Workload Management window from your vSphere client:
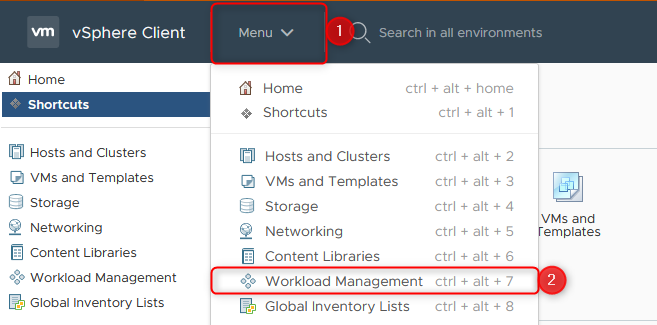
Where to find Workload Management
You’ll be prompted to activate Workload Management, and right after you’ll see the following screen:
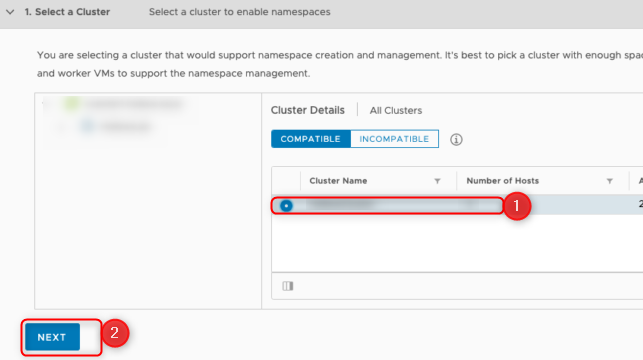
choose a cluster for your Workload Management
Here typically you would just select the displayed cluster right within the red box, and click next. When it’s empty, you’ll follow the troubleshooting further down in this post. Otherwise select it and click next.
The last step, before it get’s interesting, is to choose the cluster size
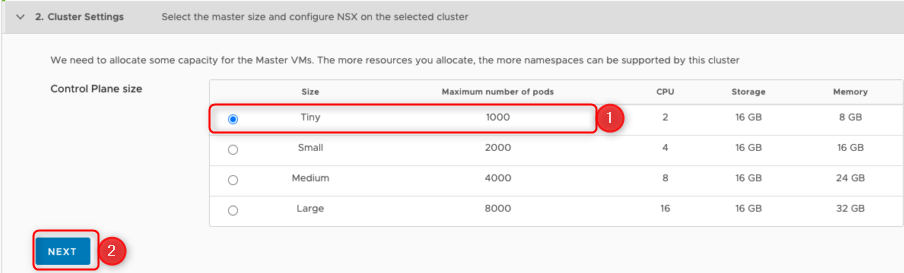
how many pods do you intent to manage in the supervisor cluster?
In our use case, as we want to utilize mostly TKG clusters, we’ll choose the tiny version. A single TKG Cluster with 3 control plane nodes and 7 worker nodes will consume only 10 pods, therefore it’s possible to install up to 100 of this huge clusters.
The Management Network
Let’s start by taking a look at the network configuration plane of a Workload Management cluster.
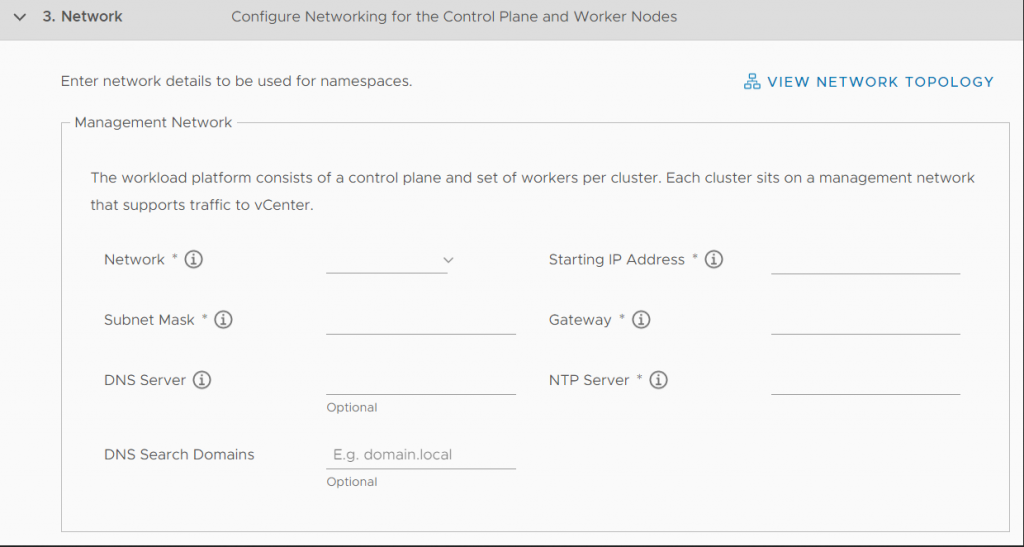
greyed out input mask for the Workload Management Cluster
Workload Management will install 3 VMs in this network. These 3 VMs need to access vCenter, as the description tells us. Also, the description mentions „Each cluster“ which refers to a Supervisor Cluster. We’re currently setting up one of these. If you want to create another Supervisor Cluster, you’ll need another ESXi Host Cluster.
- Actually, you can use every network as you wish, as long as you can access vCenter functionality out of this network.
- Starting IP Adress are 5 consecutively. If you don’t make sure these 5 IPs are not used for other purposes, you’ll lose connection and risk that suddenly nothing works anymore, if another host comes up on this IP – The SupervisorControlPlaneVMs won’t be reachable anymore.
Remember this: we need to access vCenter functionality. Nothing more, nothing less.
What does happen to the ESXi Hosts? The SupervisorControlPlaneVMs instruct vCenter to install a bunch of software onto the ESXi hosts, and ready them up to be used as kubernetes worker nodes.
The Workload Network
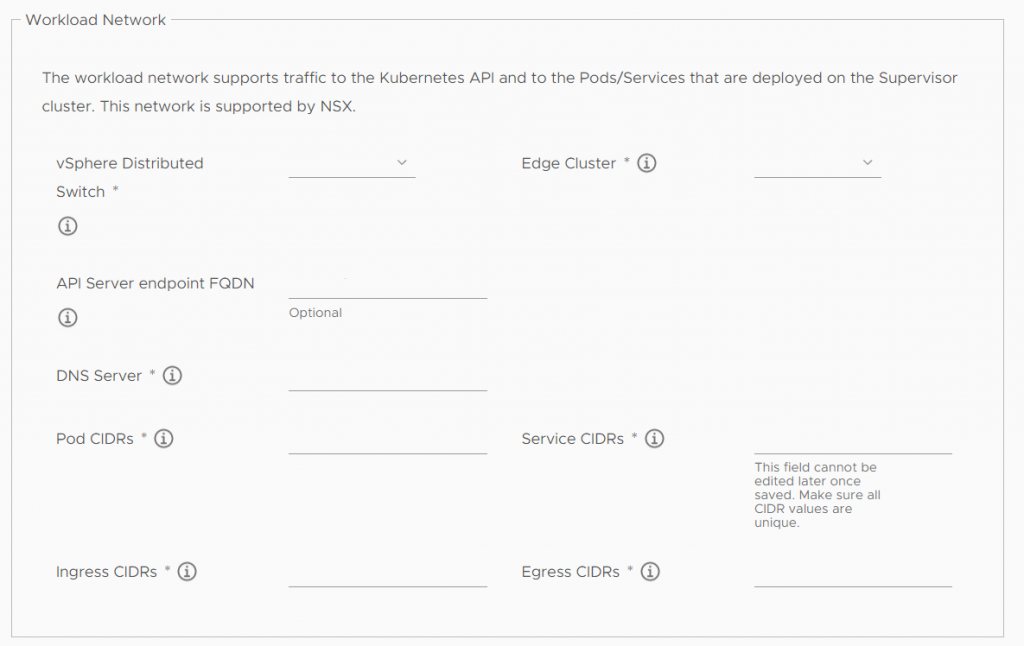
greyed out workload network configuration mask
Choose a distributed switch, and an Edge Cluster, where your traffic of the kubernetes pods and nodes should run through.
When creating another Edge Cluster be warned and set them up accordingly. If your e.g. Edge Cluster does not have a Form Factor of „Large“ you’ll need to create another one, which fulfils these prerequisites.
The Pod CIDRs are prefilled based on your chosen cluster size (e.g. how many Pods you’ll be able to create, and therefore how many IPs you’ll need, as kubernetes works with the principle “IP-per-Pod”. This is a network, which should NOT be routed, it’s used by kubernetes internally.
Service CIDRs follows the same principle. In Kubernetes you’ll specify a service, which will aggregate multiple Pod IPs. They’re mostly used for kubernetes internally. Yes, you can specify services of type LoadBalancer, but we’ll define them in the next step.
Ingress CIDRs network must be routed within your architecture. When a developer wants to access kubernetes Pods from outside of the world, he’ll specify a Service of type LoadBalancer. You theoretically could use IPs given by your Internet Provider, but it’s not necessary. Make sure, that nothing overlaps this network, or the developer won’t see why his service does not work.
Egress CIDRs allow Pods to call outside of their cluster. Kubernetes will NAT the Pod IPs into one IP of the Egress CIDRs. It’s not necessary that this network has public IPs. It’ll be NATted again, when hitting your gateway.
Storage Policies
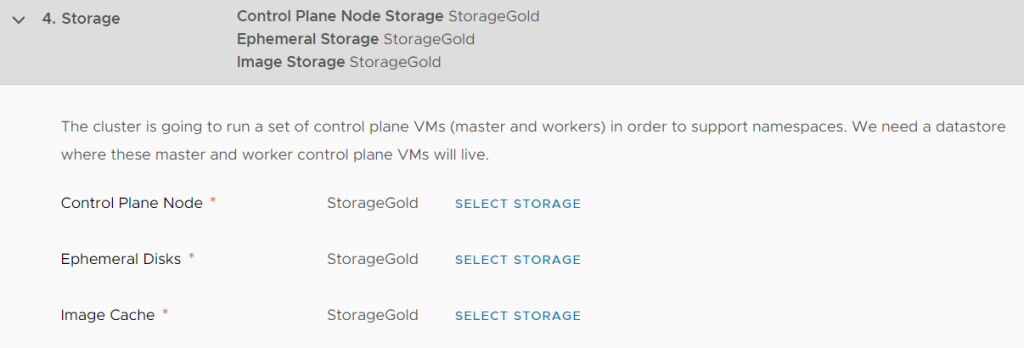
workload management storage configuration mask
This is straight forward. Where can I save what? This is only for your Supervisor Cluster. Furthermore, it’s possible to change this.
You most definitely can use existing ones, without thinking too much about this step, or you’ll define your own.
Errors, errors everywhere, where should I look?
When you’re just getting ready with networking, you’ll probably hit one or two or another 100 errors (exaggerated, but yes, I was searching… and searching…)
You actually have multiple places to watch out for your errors.
- connect to the vCenter as root and read the wspsvc.log or the nsxd.log (both in the same directory)
- on the ESXi hosts /var/log/vmkernel.log
- in NSX, check Tier 1 for errors
- utilize DCLI for obtaining additional information
Errors I’ve hit while setting up Workload Management.
No suitable Cluster found for Workloadmanagement
You have HA and DRS enabled, but the wspsvc.log tells you the following
Cluster domain-xxxxx (=your domain) is missing compatible NSX-T VDS.
My problem regarding this error was somewhat misleading, as one ESXi Host was on red, and not fully running.
- Make sure that NTP is set up on each ESXi Host, or at least the time should be somewhat identical
- Make sure each ESXi Host has at least no error (when it’s not correctly working it’ll later bite you again, but we’ll see).
Error: Timed out waiting for ifaces coming up
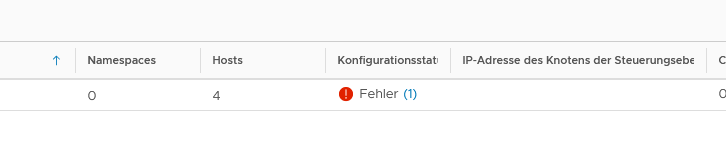
the supervisor cluster hints it has an error
Your Workload Management is at least at the point, where it’ll show you cluster configuration errors? One step forward!
We’ve got error at this point and a click on the (1) reveals the detailed error message:
On the master node … occurred an error. Details: Timed out waiting for ifaces to come up..
Well. One ESXi Host was not installing properly. This per se should not hinder the Supervisor VMs interfaces to be started, but it does. Confusing.
A closer look at the ESXi Hosts log was revealing the following error

the exact log files of the esxi hosts, which hinted the problem
Yes. It was a DNS error. A single ESXi Host died, it was set up again, but this small part was forgotten. You just should learn from this error, that even ESXi Host logs can be helpful while troubleshooting cluster configuration problems.
A T1 Error.. insufficient ressources.. Load Balancer..
So, the final and most annoying error was this: when I checked NSX T1 Gateways, which is created in the provided Edge Cluster from the Workload Management:
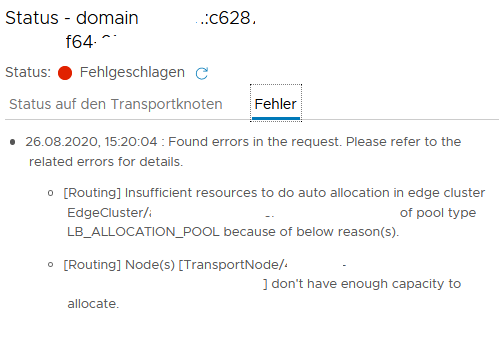
displayed error messages of the nsx interface regarding a T1 Gateway created by Workload Management
Quite fast you’ll find this horrifying Knowledge Base article with these causes:
Multiple Tier-0 router on same Transport Zone is not supported by design
Insufficient NSX resources for creating the Load Balancer.
Well, now I’ve needed our network admin. He created new Transport Zones, new uplink profiles, added routing, BGP on the physical switches, created uplink profiles etc. everything what’s necessary, to help me fix this error (this surely is its own post, but not covered by me).
And this is the part, where reading is… well… saving you time. Prerequisites for an Edge Cluster, as earlier said, is at least a Form Factor size of large. And when Workload Management does want a large Form Factor, you better provide a large Form Factor and don’t overlook this small detail, or your problem won’t go away.
Next Steps
This post should have improved your understanding regarding what you’ve set up, especially considering the Management and Workload Networks. Additionally, I have shown you all the different troubleshooting endpoints I identified on my road.
The next post sets a focus on logging in to the Supervisor Cluster and setting up a TKG Cluster within a freshly created namespace.
Recent Comments