
„Welche Performance-Einbußen ist man bereit zu akzeptieren“?
VMware vSphere 6.5 bringt im Rahmen der HA-Funktionalitätserweiterungen ein Features namens „VM ressource and availability service” mit.
Die Erweiterung basiert auf einem bereits im vergangenen Jahr unter Mitwirkung von Duncan Epping (Chief Technologist – Storage und Availability bei VMware, Autor des HA Deepdive und Macher des Nr.1-VMware-Blogs Yellow Bricks) veröffentlichen Fling names vm resource and availability service.
Das Fling ermöglicht im Rahmen der Planung der Failoverkapazität (Admission Control) eine Art „Was-wäre-wenn“Analyse in Bezug auf eintretende Host-Ausfälle. Der Administrator kann den Ausfall von einem oder mehreren Hosts im Cluster simulieren und dabei herausfinden …
• Welche VMs sich sicher auf anderen Hosts neu starten lassen
• Welche VMs nicht sicher auf anderen Hosts neu gestartet werden können
• Welche VMs nach dem Neustart auf einem anderen Host mit reduzierter Performance laufen.
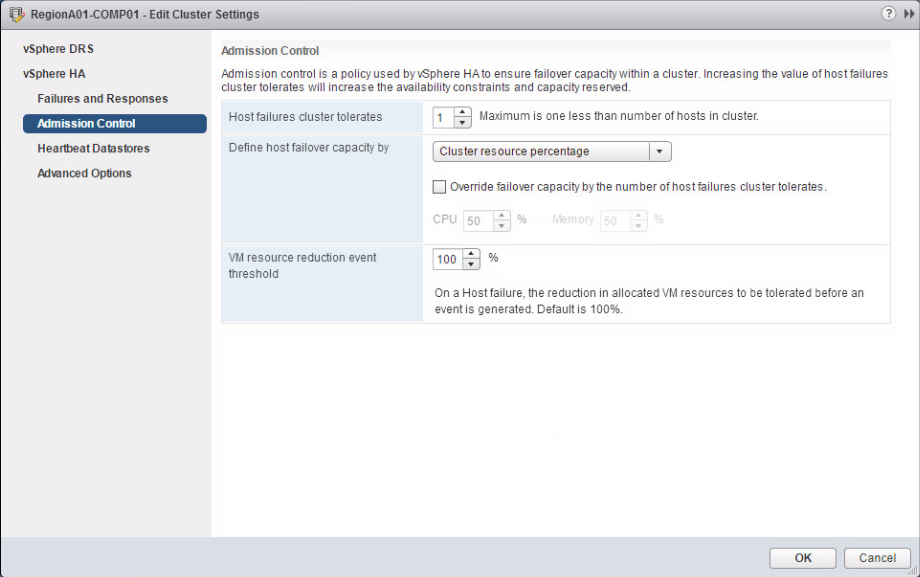
VM resource reduction event threshold
Im bereits im 1. Teil vorgestellten überarbeiteten Web-Client-Dialog für die Admission-Control-Einstellungen gibt es jetzt analog zum erwähnten Fling die neue Einstellung „VM resource reduction event threshold”.
Die Einstellung erlaubt dem Administrator das Angeben eines Performance-Verlustes, den er beim Neustarten von VMs auf einem anderen Host im Fehlerfall zu akzeptieren bereit ist. Der Default-Wert ist 100%, abhängig von den SLAs im Unternehmen könnte man jetzt aber auch 30 % oder 0 % einstellen. Voraussetzung dafür ist, dass DRS aktiviert ist. HA benötigt DRS, um die Cluster Resource Usage zu erhalten.
Hat man in einem 3-Node-Cluster beispielsweise 96 GB RAM (3x32GB), der Wert bei “host failure to tolerate specified” steht auf 1, alle laufenden VM konsumieren aktuell 70 GB RAM und der Wert bei “VM resource reduction event threshold” steht auf 0 % führt dazu in der Analyse zu einer Warnmeldung. Warum ?
Beim Ausfall “eines Hosts” wären in Cluster noch 64GB RAM verfügbar (96GB -32 GB). Es werden aber 70GB für laufenden VMs benötigt, wenn diese auf den verbleibenden 2 Hosts neu gestartet werden, weil ja per Definition (0 %) keine Performance-Verluste in Kauf genommen werden sollen. Die Konsequenz ist, dass der Admin die verfügbare Failover-Kapaität erhöhen muss, will er keine Performance-Einbußen im Fehlerfall hinnehmen.
Recent Comments