
High Availability Admission Control, Part 2
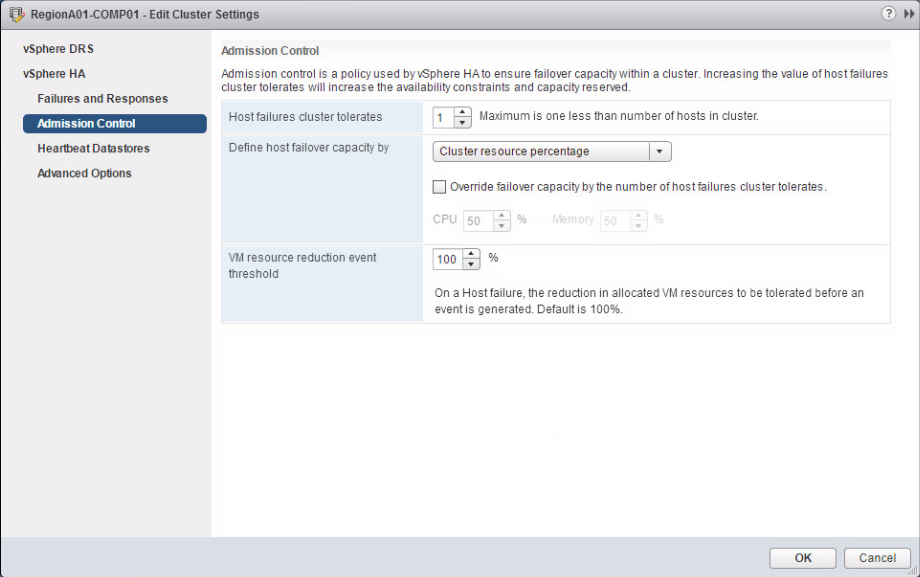
„VM resource reduction event threshold” allows the administrator to specify the performance degradation which he is willing to accept in case of a failure.
VMware has announced the upcoming vSphere release 6.5 at VMworld Europe Barcelona in the middle of October as part of its new cross-cloud-architecture. Apart from VMware’s strategy around vSphere 6.5, vSAN 6.5 and vRA 7.2, I will discuss some of the new features in vSphere 6.5 in this and following blog entries. After having given a short introduction in the last blog post, let us continue with some more new features in vSphere HA.
So let us take a look at further parts of the HA-enhancements in vSphere 6.5,
In special we want to talk about Admission Control enhancements. Basically, the enhancement are based on an older Fling called “VM resource and availability service” (see here), which was provided by Duncan Epping (Chief Technologist at VMware) and the author of the vSphere 6 HA deep dive. Altogether, several parts of the Fling from February 2015 will thus become an integrated feature of vSphere 6.5.
VM resource and availability service
The Fling enables you to perform a “What-if analysis” for host failures. Administrators can simulate failure of one or more hosts within a cluster and identify how many ….
- VMs would be safely restarted on different hosts
- VMs would fail to be restarted on different hosts
- VMs would experience performance degradation after restarted on a different host
“VM resource reduction event threshold” allows the administrator to specify the performance degradation which he is willing to accept in case of a failure. Per default, it is set to 100%. Depending on the SLAs in your company or other criteria, it is possible to set this value for example to 50 %. But how does it work?
First, DRS has to be enabled as HA leverages DRS to obtain the cluster resource usage. Let’s say, you have 96 GB RAM in a 3-node-cluster and you specify the admission control policy “host failure to tolerate specified” to 1. Let’s further say, 70 GB RAM are actively used by your virtual machines and you set the “VM resource reduction event threshold” to 0 %. What will be the result?
In order to have the answer, let’s do some calculations. How much RAM will be available in the cluster after a failure of one node? 96GB minus 32 GB (remember policy=1 host failure to tolerate) = 64 GB. Howerer, you have 70GB of memory used by your VMs and 0% resource reduction to tolerate.
So, this 70 GB needed by VMs and 64 GB available after failure will cause a warning issued to the administrator. Now you are able to guarantee, that the performance for you workloads after a failure event is close or equal to the performance before a failure event.
Recent Comments