
We have already discussed the architecture of a vRealize Automation environment in chapter two. Many topics, including the physical, conceptual and logical design have been covered. These design documents helped us to set up a vRealize Automation environment.
However, in order to proceed with the configuration of vRealize Automation, we again need to shift our focus towards the design aspects of implementing a vRealize Automation platform. This chapter will help you to understand these fundamental design concepts. In the following, we will focus on the different components as well as on security aspects. For the most part, this chapter deals with describing the building blocks within a vRealize Automation environment. Afterwards, it will end up with discussing a couple of further design aspects. This chapter will only focus on design issues. The implementation itself will be described in the following chapters.
6.1 vRealize Automation Layers
Traditionally, one of the key requirements for software is that it is maintainable, modularized and extensible – hence, a monolithic approach is not recommended nor feasible. In order to achieve this goal, software usually follows a layered software architecture. A layer provides a certain set of functionality. Higher levels use functionalities of lower levels and provide functionality by themselves. Not surprisingly, vRealize Automation also takes advantage of such a layered approach, however, not only for its internal implementation, but also for the setting up of your enterprise cloud architecture. That’s reason enough to take a deeper look at these layers.
Broadly spoken, a vRealize Automation cloud can be viewed as a system consisting of five layers:
- Layer 1 – Infrastructure: This layer entails your virtual environment, physical servers, but also the public cloud. Essentially, this is the infrastructure you are managing with vRealize Automation.
- Layer 2 – Infrastructure fabric: The infrastructure fabric encompasses all the infrastructure resources, i.e. where you want to deploy your workload. In order to work with these resources, you have to configure endpoints, which store the connection information along with the required credentials in order to communicate with them.
- Layer 3 – Fabric groups: Fabric groups help to divide the infrastructure into smaller compartments. This helps to make your infrastructure more manageable. A fabric group corresponds to compute resources such as vSphere clusters. Fabric groups can be further divided into reservations, which identify resources in a more fine-grained fashion (CPU, memory, disk, network).
- Layer 4 – Tenants: Tenants represent organizational units in vRealize Automation. They allow the provisioning of resources (e.g., virtual machines). Different tenants can be mapped to the same fabric group or can have their own dedicated fabric group (for example, in order to provide hardware isolation between tenants). Tenants are connected to a directory service like Active Directory for user management.
- Layer 5 – Business groups: Analog to fabric groups, business groups help to group users of the self-service portal for ease of management. In daily life, business groups are usually mapped to organizational units such as teams (for example, financial teams, Dev Ops Teams) or departments.
Fig. 1 depicts the vRealize Automation layers. Now let’s discuss these layers in detail.
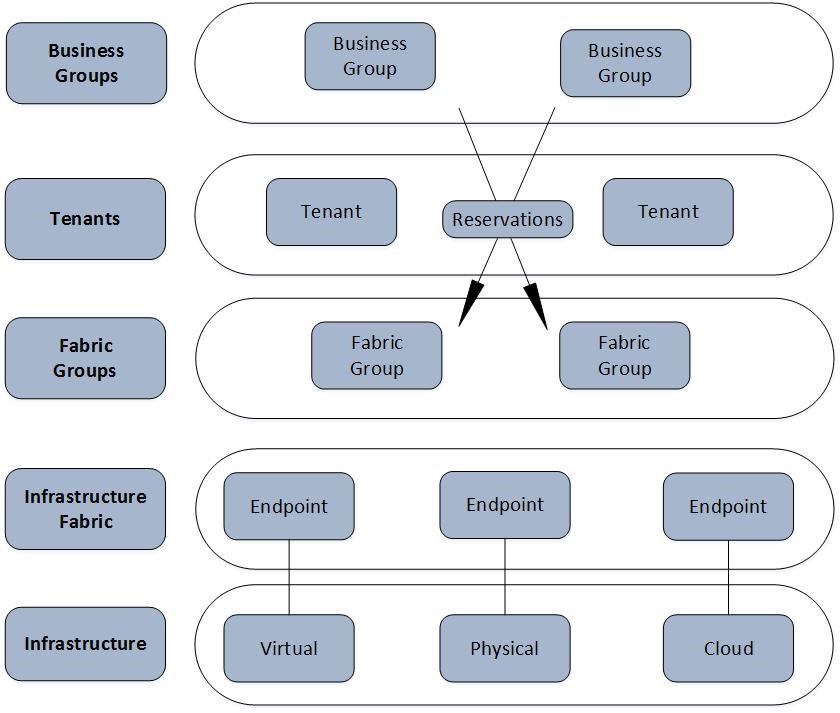
Fig. 1: vRealize Automation layers
6.1.1 Infrastructure layer
As discussed, the infrastructure layer represents the hardware where you are deploying your workload to. If you are setting up your cloud infrastructure within your existing environment, that includes your current vCenter servers, hypervisors, physical servers or any public cloud you are already working with. If you are implementing a green-field approach, there will be new infrastructure resources as well. In any case, some considerations regarding your infrastructure should be done. This includes the question where you want to deploy your workload – for example you might have different geolocations. Usually, it is recommended to place the servers close to end-users to have lower latencies when working with these resources. Depending on the type of your provisioned workload, additional requirements could arise. For example, some workload might have some licensing restrictions. If you want to offer different service tiers, it is always good practice to group servers which serve the same workload to a cluster.
Quite often the administration of the infrastructure resources is separate from the other layers of the cloud. Hence, you have to make sure to have all the required credentials to connect to the infrastructure and to be able to deploy any workload.
6.1.2 Infrastructure fabric layer
The next step in the configuration process of a cloud enterprise solution is to connect the infrastructure resources to vRealize Automation. The whole set of resources that is connected and managed by vRealize Automation is called the infrastructure layer. Administrators have to setup endpoints in order to bring these resources under control of vRealize Automation. The most important type of endpoint is – in most environments – the vSphere endpoint. A quick recap: the two entities that are managed at the infrastructure fabric layers are:
- Endpoints
- Compute resources
vRealize Automation not only uses endpoints for the provision of resources, it also uses them to gather information about its environments. For example, if you want to provision virtual machines by cloning a template, vRealize Automation must be able to receive information about existing templates to feed its own databases and update this from time to time, a process called ‘data collection’.
There are several different endpoints available. The most important ones are as follows:
- vSphere (vCenter Server)
- Hyper-V
- Microsoft System Center Virtual Machine Manager (SCVMM)
- KVM (Red Hat Virtualization Server)
- Xen Server
- vCloud Director
- vCloud Air
- Amazon AWS
- Red Hat Open Stack
- Dell iDrac
- HP ILO
- Cisco UCS
- VMware Orchestrator
- NetApp Flexclone
Once you have finished the setup of an endpoint, vRealize Automation can use the underlying compute resources. There is a 1:n relationship between an endpoint and its compute resources (see Fig. 2). An endpoint represents the connection information to connect to certain compute resources. There are different kinds of compute resources – they can be vSphere clusters, Hyper-V hosts, virtual datacenters or even Amazon AWS regions.

Fig. 2: Compute resource and endpoint relationship
While endpoints are needed, vRealize Automation does not use them directly to communicate with the underlying systems. Instead, DEMs and/or agents are used. Please note that you must install and configure an agent for some hypervisors, whereas for others you can skip this step (this depends to what you want to connect to).
The vSphere agent is usually installed by default when performing a full installation of vRealize Automation. This means there is usually nothing to do other than to check if vSphere agent is running as a Windows service. However, during the installation you also specified the endpoint name the vSphere agent is connected to (there is always a one-to-one relationship between a vSphere agent and a vSphere endpoint). So when creating an endpoint, it must be made sure that the endpoint name is the same as specified during the installation.
| Endpoints in vRealize Automation
This chapter focuses mainly on vSphere endpoints. However, as there are many kinds of endpoints, we want to briefly describe them: A vCloud Director endpoint is used to connect to vCloud Director. vCloud Director uses vSphere to provision resources. Therefore, take care not to duplicate resources whilst importing, i.e. at the same time using the vSphere endpoint and the vCloud Director endpoint for managing exactly the same set of resources. A vCloud Air endpoint is used to provision resources in a vCloud Air datacenter (as opposed to an on-premise location). A Microsoft SCVMM endpoint allows the communication with SCVMM 2012 for provisioning. However, there are some smaller issues to consider: The DEM worker must be installed on the same machine as the Microsoft SCVMM console. Furthermore, the DEM worker needs access to Microsoft PowerShell, with a PowerShell Execution Policy set to RemoteSigned or Unrestricted (Set-Execution-Policy unrestricted /RemoteSigned). If you want to directly communicate with a Hyper-V host, you also have to install a Hyper-V-proxy agent. To provision an Amazon Web Services (AWS) EC2 instance, you will need an AWS endpoint. You have to configure your credentials with the Amazon access key and secret key. Furthermore, you must specify the region you want to provision resources to. A Red Hat Open Stack endpoint can be used to provision resources to an Open Stack-based cloud. VMware supports the Icehouse, Juno and Kilo version. In addition, VMware supports its own distribution, VMware Integrated Open Stack, in version 2. The Red Hat Enterprise Virtualization KVM endpoint allows for provisioning to KVM. Currently, version 3.1 is supported. You can also communicate with a Xen-Server environment (5.6 through SP2, 6.0.2, 6.2 through SP1), however there is an agent required as well. Orchestrator endpoints permit adapting the lifecycle of your provisioned resources. Physical endpoints are required to manage physical machines within vRealize Automation. Currently only Dell iDrac, HP iLO and Cisco UCS Manager are supported. Storage endpoints can be used to directly communicate with storage arrays and take advantage of their specific features. For example, having a NetApp with preconfigured Endpoints can enhance your provisioning by making use of NetApp Flexclone technology. |
6.1.3 Fabric group layer
The next higher layer in vRealize Automation is composed of fabric groups. Fabric groups are used to group your compute resources into different manageable entities in order to be able to configure these groups separately. In other words, a fabric group can be understood as a policy that defines the relationship between all kinds of compute resources and a chosen administrator who can slice them into virtual datacenter (VDCs) for consumption (this will be referred to as reservations). There are several reasons to have your resources organized in different fabric groups – for example, if you want to isolate your hardware resources from each other so that different departments cannot share them. The fabric group layer is slightly more complex than the layers described before as there are many different components that have to be managed:
- Machine prefixes
- Network profiles
- Reservation and reservation policies
- Amazon EBS volumes and key pairs
- Compute resources
Let’s talk about these concepts in detail:
6.1.3.1 Machine prefixes
When vRealize Automation provisions machines on behalf of users, it needs to assign a machine name. While it is theoretically possible for a user to specify a hostname manually, in most environments this process should be automated. vRealize Automation provides a simple mechanism that creates hostnames automatically – a machine prefix. A machine prefix consists of a name and a number that is appended to that name. Every time a new machine is created, the number will be incremented. For example, if you create a machine prefix of ‘vdc’ plus three digits, your hostnames would be vdc001, vdc002, vdc003 and so on. It is also not required that your machines start with number “1”, higher numbers are also possible. However, there are some restrictions for the machine prefix string:
- They have to adhere to DNS naming conventions, i.e. they can only contain ASCII characters from a-z, A-Z and digits between 0-9. Any other special characters are not permitted.
- If a machine prefix is used for provisioning Windows machines, there is a maximum length of 15 characters in total.
However, in many cases enterprises have more complex requirements for machine names. In such scenarios, using machine prefixes might not be sufficient and there is the need of some custom logic to define a custom hostname. In such cases, vRealize Orchestrator can help you with implementing such a logic. In any case, you should have some conventions for the naming of machines in your enterprise. Having such a design can bring you many benefits:
- Users can find and properly use cloud resources more easily.
- Management of cloud resources is simplified.
When you create such a design, please consider that shorter and simpler standards are preferred over cryptic ones that are hard to use. A naming convention can be based on different criteria:
- The location where a resource is getting deployed to. For example, each machine name could have a prefix indicating the datacenter.
- The department or business group which is the owner of the resource. If the name is too long for the machine name, consider the use of short IDs.
- The operating system of the virtual machines. Many companies use a ‘X’ for Linux operating systems and a ‘W’ for Windows machines.
- The function of the server could also be indicated. Hence, all servers of the same type could easily be discovered.
- The tier level of the machine (a machine could have a gold, silver or bronze level).
On the other side, when putting all this information into a machine name, there is not too much free text left to be specified by your consumers. However, you could use Orchestrator to indicate that meta-data in other ways as well. Many enterprises create different vCenter folders for different kind of virtual machines (an orchestrator workflow could then place a virtual machine into a specific subfolder based on that metadata as well).
Now that you have understood the basic theory behind naming machines, let’s discuss the possibilities to enforce a consistent way to apply naming conventions. In summary, the options can basically be described as follows:
- The out-of-the-box machine prefix is actually only good for simple scenarios. Machine prefixes can be either attached to business groups or blueprints, so they are useful for two scenarios. First, you have a 1:1 relationship between your business group and your hostname format, or second, you have a 1:1 relationship between your blueprint and hostname format.
- Use the hostname custom property (we will discuss custom properties extensively when talking about extensibility). The hostname custom property allows a user to enter the hostname when they are requesting their item from the catalog. This is a very simple approach, but only recommended for POCs or demo environments. The problem is that hostnames must be unique in many environments (for example, in vSphere), however, when requesting a virtual machine users have no possibility in vRealize Automation to check if a hostname is already assigned (if there is a clash, the provisioning process fails).
- There is a free plug-in written by Tom Bonanno[1], which can be obtained from his blog dailyhypervisors.com. The plug-in must be installed in Orchestrator and allows you to easily define many naming standards (where hostname is comprised of codes like location, server type, OS and so on).
- The last option is to implement your own workflow and define your own custom logic. We will show how to do this later when dealing with Orchestrator.
To conclude with machine prefixes, we also have to state that one of the most powerful options has not found its way into the current release of vRealize Automation: Generate random hostnames and use tagging to assign metadata to the provisioned machine. Anybody who has worked with Amazon Web Services before knows that this option is by far the best solution and lets plenty of room for extensibility.
6.1.3.2 Reservations and reservation policies
Reservations and reservation policies are the most important concepts that we have to talk about with regard to the fabric group layer. However, these two components break somehow the layered approach. Basically, the question arises how to grant business groups access to hardware resources so that they can deploy workloads. That’s where reservations come into play.
Many of you are already familiar with the concept of reservations from vSphere. However, the reservations in vSphere only share the name with the reservations in vRealize Automation. In reality, they are completely different concepts. Reservations in vRealize Automation are a way to determine how many resources of the underlying infrastructure are mapped to consumers. In addition, it is important to understand that there are different kinds of reservations:
- A virtual reservation allocates parts of virtual resources. For example, when referencing a vSphere cluster, you will specify which share of the cluster (i.e. how many vCPUs, the size of the memory, which datastores or networks are to be used) will be assigned to a business group. For example, you might have a vSphere Cluster for your production environment which contains 2048 GB of RAM and 2 TB of storage. Once you have created a fabric group based on that underlying resources, you can use a virtual reservation to determine that the marketing business group gets 512 GB of RAM and 1 TB of storage. Consequently, there can be more than one reservation for a virtual compute resource.
- A physical reservation always allocates the whole machine. It is not possible to have multiple reservations on the very same hardware. If another reservation is needed, you will have to delete the existing one first.
- You can also have reservations in a cloud environment. To configure a cloud reservation for AWS, you need to configure an AWS endpoint first. For vCloud Director you need a vCloud Director endpoint, respectively.
| Visibility of resources
vRealize Automation will display all available compute resources when configuring a reservation. If you want to restrict visibility, it is a good idea to create a special service account for vRealize Automation in vSphere. There are plenty of objects in vSphere, which should not be visible in vRealize Automation – for example it makes no sense to connect resources to the vMotion network. So consequently it should not be available in the user interface. If you want to restrict visibility in vSphere, you can also use the No Access permission to restrict access. |
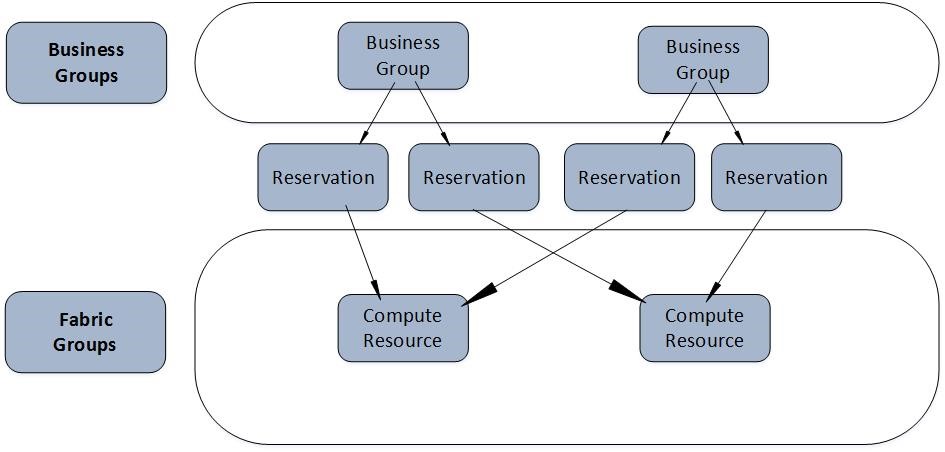
Fig. 3 Business groups and reservations
We have already mentioned, that reservations somehow break the vRealize Automation layered approach. Usually, lower layers provide services to upper layers. However, in the case of reservations you have to create a business group first, because a reservation links a business group to a compute resource within the fabric group.
Fig. 3 shows the relationship between business groups and reservations. Each reservation represents a 1:1 relationship between a compute resource and a business group. However, it is possible that multiple reservations are tied to a business group. There might be different reasons for this:
- First, you might want to balance your workload on different compute resources. You can control that by setting a priority on each reservation. If all reservations have the same priority, vRealize Automation will use a round-robin algorithm to balance the workload among different reservations.
- Another use case is to set up a fail-save reservation and use it in cases you run out of capacity in your main reservation. Once again, you can configure this behavior by setting up the priority value of the reservation. By default, vRealize Automation selects the reservation with the highest priority. If that reservation has run out of capacity, the reservation with the next highest priority will be used.
- Different reservations can also be used to place different workload in different compute resources. There are also plenty of use cases for that. For example, you might decide to implement different service tiers and hence, to set up different clusters for these tiers. Later on, you want to let your customers choose to which service tier they are provisioning their workload to. However, in order to implement such a scenario, we also have to configure reservation policies in advance.
Reservation policies
Reservation policies are used if your business group has several reservations available, but you need to restrict which reservation should be used for a deployment. In practice, a reservation policy can be used in many cases. For example, a desktop machine will probably have different hardware requirements compared to those of an SQL Server. Consequently, you could have two different fabric groups – one fabric group called “Bronze FG” with entry-level performance and another fabric group called “Gold FG” with high-performance hardware. Now you could deploy desktop machines to the Bronze FG and SQL Server to the Gold BG. Other reasons for reservation policies are security requirements, software licensing isolation or other SLO driven needs.
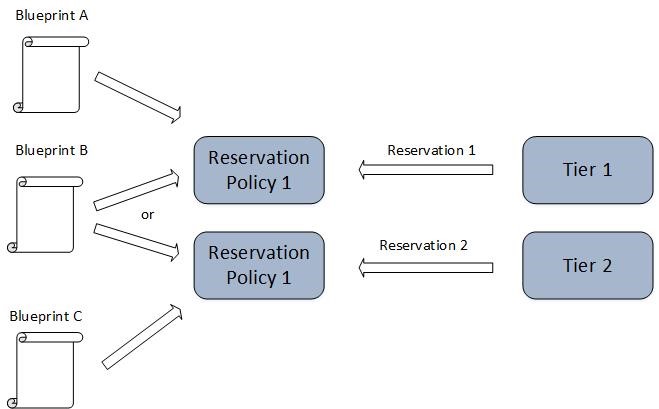
Fig. 4: Reservation policies
Technically, reservation policies simply connect blueprints and reservations (blueprints specify the machines to be deployed). Fig. 4 shows such a mapping.
Storage policies
In addition to the normal reservation policy, there is also a second kind of reservation policy – storage reservation policies. From a conceptual point of view, they are quite similar to standard reservation policies. However, they specifically apply to storage volumes.
In addition, it is well-known that within vSphere, VM storage policies exist as well. You can use those storage policies to manage storage tiers in your vRealize Automation cloud without using vRealize Automation storage policies. In order to configure such tiers, you have to do some configuration work (we will only shortly summarize the basic steps to be done, as this is a vRealize Automation book, and not a vSphere book):
- First, set up your VM storage policies in vSphere. This involves creating tag categories for storage and tags for the different kinds of storage. Then assign these tags to the different datastores. Once done, create VM storage policies based on your user-defined tags.
- The next step is to create a seperate template for each storage tier and each template in vSphere and assign each template to a VM storage policy.
- The last step is done in vRealize Automation: Create one machine blueprints for each virtual machine template.
Using this way, any virtual machine that is deployed from a template is automatically deployed to the correct datastore based on the underlying VM storage policy. It is noteworthy, however, that such a configuration also has some disadvantages. Because vRealize Automation does not directly interact with VM storage polices, vRealize Automation is totally agnostic to that feature. As a consequence, setting up an own template for each storage tier and each virtual machine can result in a lot of templates to be managed.
6.1.3.3 Network profiles
When a machine gets provisioned, it will usually be connected to a network. Which network is taken depends on the reservation (if there is more than one network available in the reservation, vRealize Automation selects a network by using a round-robin algorithm).
Another problem is how to configure the network settings for a virtual machine (i.e. the IP address, default gateway, subnet mask, DNS server). The answer is that, by default, vRealize Automation will let the underlying network provide these values. So if you have a DHCP server configured in that network, everything is fine. However, from time to time you do not want to rely on an external network’s settings, but configure everything by yourself directly within vRealize Automation. Network Profiles help you to do most of the configuration settings directly in vRealize Automation. There are three different kinds of Network Profiles:
- External Network Profiles reference networks which are configured on the vSphere server and are the external part of the NAT and routed network types. When configuring an external network profile, you can define a range of static IP addresses that are available on the external network. External network profiles are also a prerequisite for NAT and routed network.
- Routed Network Profiles allow a segmentation of an IP address area with its own routing table. Routed Networks need a Distributed Logical Router (DLR). Hence, they are only available if you have NSX integrated into your cloud environment. Routed networks are created at runtime. We will cover Routed Network profiles later in detail.
- NAT Networks comprise a private network, where you deploy your virtual machines, and an external network that is connected to the private network via a NAT Router. Just as routed networks, they are created at runtime. We will cover them later in detail as well.
We will discuss the details of network profiles later – when talking about the NSX integration.
6.1.3.4 Amazon key pairs and EBS volumes
Amazon EC2 uses public–key cryptography to encrypt and decrypt login information. Public–key cryptography uses a public key to encrypt a piece of data, such as a password. Then the recipient uses the private key to decrypt the data. The public and private keys are known as a key pair. Consequently, vRealize Automation has to manage these key pairs as well – and this is done at the fabric group layer.
Besides key pairs, EBS volumes are also managed at the fabric group layer level. An Amazon EBS volume is a durable, block-level storage device that you can attach to a single EC2 instance. The lifecycle of an EBS volume can be tied to the EC2 instance. In many cases, however, the lifecycle is independent from the virtual machine, so it makes perfectly sense to manage it at the fabric group level as well.
6.1.4 Tenant layer
The concept of tenants and multi-tenancy is one of the most important concepts within cloud computing, so it is important to discuss how multi-tenancy is addressed in vRealize Automation and how it can be configured. Basically, in vRealize Automation, a tenant has the following characteristics:
- Multi-tenancy allows the operation of shared software and hardware resources in a way that they can be mapped to independent instances or applications belonging to different customers. For example, this means that virtual machines belonging to different customers (and are managed separately) can run on the very same hardware. Consequently, tenants are isolated from another, but can use a common infrastructure.
- Depending on the customer’s requirement, the workload of different tenants can run on the very same hardware, but from time to time it might be required that each tenant uses his own dedicated hardware. As an example, think about the license agreement of big software vendors stating that the host where the virtual machine is running is solely dedicated to this particular customer.
- A tenant usually maps to some kind of organization or organizational unit, and in this way it can manage its own users and groups. The identity sources which those users and groups come from, may be shared across different tenants or might be unique to each tenant. A tenant might be connected to different identity sources as well.
When talking about fabrics and fabric groups, we have stated that there are a lot of items that are not specific to individual tenants. However, on the other side, there are a lot of things which are specific to each tenant. Let’s enumerate them:
- Blueprints
- Business Groups
- Service entitlements
- Service catalog offerings
- Approvals settings
- Management portal URL
- Advanced Service Designer settings
- Branding
6.1.4.1 Tenant Design
When setting up vRealize Automation and running the installation wizard, a default tenant is created by default. In many cases setting up a single tenant in that way is sufficient, but there might be scenarios where it is useful to think about tenant design. Basically, you have three choices for your tenant design:
- Single-tenant architecture
- Multi-tenant architecture with infrastructure configuration in the default tenant
- Multi-tenant architecture with infrastructure configuration in each tenant.
Let’s discuss all off these design choices.
Single-tenant architecture

Fig. 5: Single tenant architecture
Within a single-tenant architecture, all the configuration takes place within the default tenant. Tenant administrators manage users and groups, business policies such as approvals, the service catalog with its blueprints, the branding and so on. All users use the very same URL for logging in into the portal (https://<vra-app.domain.name>/vcac). There’s security trimming behind the scenes in vRealize Automation – so based on the user privileges, the user interface is different for each user.
From a technical point of view, the single-tenant design is the easiest one to set up and is especially suitable for small and medium organizations. It is also VMware’s most recommended design. The design is depicted in Fig. 5.
Multi-tenant architecture with infrastructure configuration in the default tenant
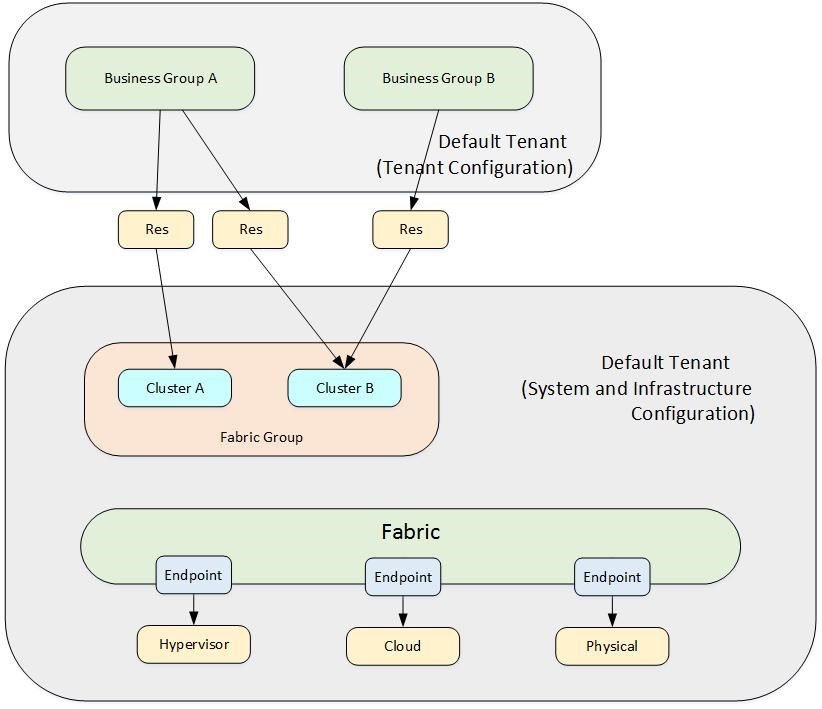
Fig. 6: Multi-tenant configuration with infrastructure configuration in the default tenant.
Setting up and managing a multi-tenant architecture is more challenging compared to a single-tenant environment. Having such a configuration means setting up a tenant for each organization or organizational unit. As stated, there are two different design possibilities for a multi-tenant architecture. We will first talk about the one having all the infrastructure configuration in the default tenant. This design is especially well-suited for medium and big enterprises where all the hardware resources are centrally managed and shared between the different tenants. However, the tenants can keep some form of autonomy. This includes the fact that they are responsible for user management by themselves (each tenant administers its own identity sources). In addition, each tenant can keep track of its own catalog service items, business policies and blueprints.
Fig. 6 depicts the design of such an architecture. As discussed before there is a URL strategy for the different tenants: Users can log in to the default tenant using the URL https://<vra-app.domain.name>/vcac, while access to the other tenant is possible via the URL https://<vra-app.domain.name>/vcac/org/<tenantName> .
Multi-tenant architecture with infrastructure configuration in each tenant.
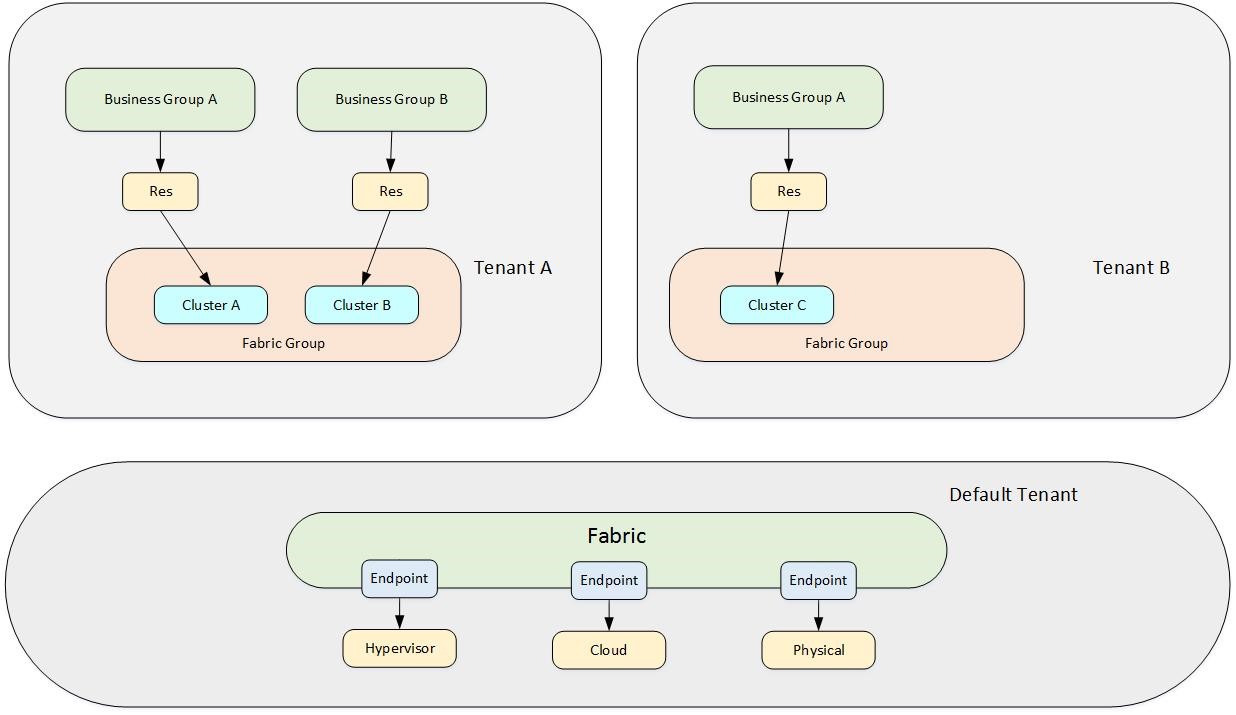
Fig. 7: Milti-tenant architecture with infrastructure configuration in each tenant
The second strategy for setting up a multi-tenant architecture allows all the tenants to manage their own infrastructure resources. There is a default tenant as well, but except the endpoints and the system configuration, there is not too much configuration being done there. This design is useful for very large enterprises, datacenters and cloud providers. As the tenants manage their own infrastructure resources, it can be guaranteed that no workload runs on shared resources. As a consequence, there is a high administrative overhead, because all the configuration items have to be set up for each tenant individually. Please also consider that this does not only involve vRealize Automation configuration items, but can also cause additional work in the underlying infrastructure as well.
For example, imagine that your tenants run on individual vCenter servers which must be managed separately as well. You can see the design of such a configuration depicted in Fig. 7.
6.1.5 Business Group layer
Remember, we created fabric groups in order to isolate entities for managing hardware resources. Analogous to grouping hardware resources, we also want to group users of the self-service portal to business groups for ease of management. In daily life, business groups are usually mapped to organizational units such as teams (for example, financial teams, DevOps teams and so on) or departments.
Once created, business groups must be mapped to fabric groups. That way they will have permissions to provision resources (we have already discussed how business groups can be mapped to compute resources via reservations). On the other side, there are entitlements – we will discuss them in detail in a later chapter – which control what kind of items can be selected by users of a business group.
Creating a business group also allows you to specify user roles within the organizational unit. vRealize Automation is aware of the following roles within a business group:
- There is at least one business group manager. This role can approve the provision of machines. Furthermore, a business group manager can check how much of the available resources assigned to the business group are currently in use. He also controls which catalog items can be requested by the members of the groups. Of course, besides being able to manage the business group itself, the manager can also provision resources himself – or on behalf of other users.
- Support users are able to provision and manage machines for themselves or on behalf of other users (this is especially useful if normal users only have the right to work with existing machines and are not allowed to provision resources by themselves. Support users can also help with managing machines of other users when those are not available (for example, if they are on a holiday).
- In order to create or manage your own machine in vRealize Automation, you must be a member of the business group – i.e. a business group user. Of course, users can also be members of many different business groups.
6.2 User role overview
We have just described the different layers within a vRealize Automation infrastructure. In addition to the basic capabilities associated with each layer, there also exists a sophisticated role model. Each of these roles only permits to carry out a subset of all total configuration work, so many companies tend to create a super user who has all the roles assigned. In addition, vRealize Automation is security-trimmed on the graphical user interface, i.e. you only see the configuration items in the menus you have been permitted access to. This can sometimes be quite confusing (especially when you do not know if you lack permissions to do something, or you just forgot where a certain configuration item can be found in the graphical user interface).
Essentially, vRealize Automation comes with three categories of roles:
- System-wide roles
- Tenant-roles
- Business group roles
System-wide roles
There are two different system-wide roles: The system administrator and the IaaS administrator. The system administrator is configured during the vRealize Automation installation process when configuring single sign-on. Once a system administrator creates and configures a tenant, the IaaS administrator is designated. The following table shows the responsibilities of both roles.
| Role | Responsibilities |
| System administrator | Create tenants |
| Configure tenant identity stores | |
| Assign IaaS administrator role | |
| Assign tenant administrator role | |
| Configure system default branding | |
| Configure system default notification providers | |
| Monitor system event logs, not including IaaS logs | |
| Configure the vRealize Orchestrator server for use with XaaS | |
| Create and manage reservations across tenants if also a fabric administrator | |
| IaaS administrator | Configure IaaS features, global properties |
| Create and manage fabric groups | |
| Create and manage endpoints | |
| Manage endpoint credentials | |
| Configure proxy agents | |
| Manage Amazon AWS instance types | |
| Monitor IaaS specific logs | |
| Create and manage reservations across tenants if also a fabric administrator |
Tab. 1: System-wide roles and responsibilities
Tenant-roles
Within a tenant, there are different roles as well: The tenant administrator, fabric administrator, blueprint architect, catalog administrator and the approval administrator. System administrators assign the tenant administrator role when creating a new tenant. The tenant administrator can assign the role to other users within the tenant at any time. The tenant administrator also assigns the other roles. The roles and responsibilities are shown in the following:
| Role | Responsibilities |
| Tenant administrator | Customize tenant branding |
| Manage tenant identity stores | |
| Manage user and group roles | |
| Create custom groups | |
| Manage notification providers | |
| Enable notification scenarios for tenant users | |
| Configure vRealize Orchestrator servers, plug-ins and workflows for XaaS | |
| Create and manage catalog services | |
| Manage catalog items | |
| Manage actions | |
| Create and manage entitlements | |
| Create and manage approval policies | |
| Monitor tenant machines and send reclamation requests | |
| Fabric administrator | Manage property groups |
| Manage compute resources | |
| Manage network profiles | |
| Manage Amazon EBS volumes and key pairs | |
| Manage machine prefixes | |
| Manage property dictionary | |
| Create and manage reservation and reservation policies in their own tenant | |
| If this role is added to a user with IaaS administrator or system privileges, the user can manage reservations and reservation policies in any tenant. | |
| Application architect | Assemble and manage composite blueprints |
| Infrastructure architect | Create and manage infrastructure blueprint components |
| Assemble and manage composite blueprints | |
| XaaS architect | Define custom resource types |
| Create and publish XaaS blueprints | |
| Create and manage resource mappings | |
| Create and publish resource actions | |
| Software architect | Create and manage software blueprint components |
| Assemble and manage composite blueprints | |
| Catalog administrator | Create and manage catalog services |
| Manage catalog items | |
| Assign icons to actions | |
| Approval administrator | Create and manage approval policies |
Tab. 2: Tenant roles and responsibilities
Business group roles
Last but not least, there are business group roles. These roles are managed by the tenant administrator as well.
| Role | Responsibilities |
| Business group manager | Add and delete users within their business group |
| Assign support user roles to users in their business group | |
| Create and manage entitlements for their business group | |
| Request and manage items on behalf of a user in their business group | |
| Monitor resource usage in a business group | |
| Change machine owner | |
| Approver | Approve service catalog requests, including provisioning requests or any resource action |
| Support users | Request and manage items on behalf of other users in their business group |
| Change machine owner | |
| Business user | Request catalog items from the service catalog |
| Manage their provisioned resources |
Tab. 3: Business group roles and responsibilities
6.2.1 Custom groups
In addition to assigning roles directly to users, tenant administrators can create custom groups as well. These custom groups can combine other custom groups, identity store groups and individual identity store users. Custom groups help to better manager highly privileged user within a tenant. Instead of setting privileges at different locations, custom groups allow the centralized role assignment within a tenant.
6.3 Advanced design considerations
So far we have discussed the basic building blocks that can be used to design a vRealize Automation cloud environment. Not surprisingly, when creating a vRealize Automation design, architects have to take the enterprise requirements as input and create a design using the aforementioned configuration items.
In the following, we want to introduce some of those design use cases.
6.3.1 Setting up custom virtual datacenter
Many customers have implemented an equivalent of an Amazon Virtual Private Cloud (Amazon VPC). Basically, an Amazon VPC can be described as an isolated network, where end users can launch virtual machines to. Users have control over the virtual networking environment, including the selection of their own IP address range, internet access, firewall rules, load balancers and so on.
Such a design can also be implemented in vRealize Automation. Some features such as load balancers and firewall rules require NSX (and will be described in a later chapter), but the basic design can be built using the described building blocks.
Once implemented, it is possible to assign one or more virtual datacenters to consumers. Each datacenter can be represented as a business group. Reservations represent the set of resources assigned to a virtual datacenter. These can be enumerated as follows:
- The underlying compute resource
- Reservation policies for service tiring
- A vSphere resource pool
- An underlying network represented as a network path (in vSphere this can be mapped to port groups)
- A network profile that helps to manage IP assignments
In addition, you can define quotas on reservations to restrict the resource consumption within a virtual datacenter.
In AWS, a VPC is located in a single region and cannot be spread between different regions. It is best practice to implement a custom virtual datacenter in a similar way and never spread resources for a business group across multiple physical sites.
If you are setting up a multi-site deployment in vRealize Automation, you will be confronted with additional complexity. We have learnt that all major vRealize Automation components must be located at the same site. However, the IaaS DEM worker servers and IaaS proxy agents should be installed in each of the remote sites.
Also consider additional hidden complexity. There will be problems like WAN latency between sites or you have to consider how to roll out new software versions or vSphere items such as templates in each of the sites connected to vRealize Automation.
6.3.2 Tiered resources
For many organizations, it is quite common to provide different service tiers (e.g. to reflect different service levels). Imagine the following scenario, where consumers can choose among three different tiers:
- Gold tier: This is the highest, most important tier. All mission-critical VMs are placed here.
- Silver tier: This is the middle tier. The majority of the production VMs are placed here.
- Bronze tier: Consumers place the majority of test and developments VMs here.
You can define tiers for cloud environment as well. Basically, you have two choices when configuring tiers. They can be defined at cluster level or they can be configured in vRealize Automation itself. Let’s discuss the two approaches.
Tiers defined at cluster-level
Many organizations define cluster at the vSphere level. Each tier is configured as a dedicated cluster (see Fig. 8). Such a configuration bears some advantages. First, all the tier configuration can be done outside of vRealize Automation and can be re-used for other applications as well. In addition, as the different tiers work on different clusters, there is resource isolation of the tiers’ workload. If one of your tiers runs out of capacity or does not use its computing capabilities, you can easily add or remove a host to or from the cluster. From a capacity management perspective, this approach is straightforward, because having tiers modeled at clusters always lets you easy find out how much capacity is left in each service tier (this can be easily done using dashboards in vRealize Operations). On the downside, there might be some wastage on the cluster-level – especially if you do not monitor resource consumption at the cluster level.
In order to implement tiers in vRealize Automation, you have to set up a reservation for each of the different resource clusters and connect it with the appropriate business group. If you want tie a blueprint to a specific tier, you additionally need to setup reservation policies.
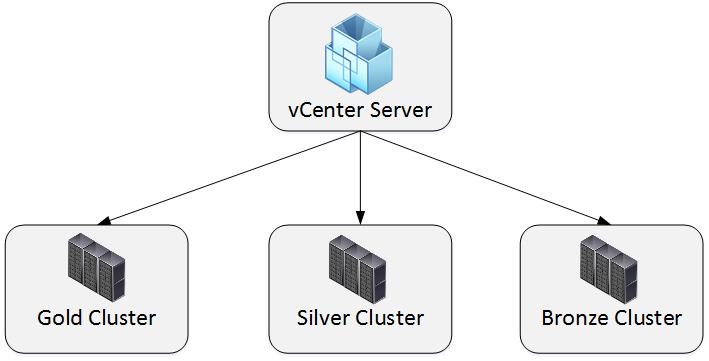
Fig. 8: Regarding storage and network, you still have the choice to share the storage across all tiers or to create a separate storage and network for each cluster.
Tiers defined in vRealize Automation
The other choice is not to take any tier considerations into account at a vSphere level and handle all the tiering configuration in vRealize Automation itself. This approach reduces the overall hardware requirements and gives business groups more control over their resources. When setting up such a solution, you have to use custom properties and Orchestrator workflows (which will be described in a later chapter).
6.4 Summary
This chapter provided an overview about the vRealize Automation tenant design. We discussed the basic tenant settings alongside with the building blocks that form a vRealize Automation environment. At the end, we concluded with some design discussion. Most of the information was mainly theoretical with only little focus on implementation. The implementation steps itself will be shown within the next chapters.
[1] http://dailyhypervisor.com/vrealize-automation-custom-hostnaming-extension/
Recent Comments